
Motivation:
When starting out with machine learning, K-nearest neighbors are among the first algorithms to study because of their understandable concept. I chose breast cancer as a dataset because it is well-documented and available. It is commonly used as a toy data set for regression and classification. Data sources from UCI Machine Learning can be found in their repository. The contents were adapted after studying AWS built-in kNN notebook.
Goal: Successfully run k-NN Algorithm with SageMaker
Objective:
- Down-select Features
- Create kNN model
- Use protobuf
- Create SageMaker estimator
- Make Predictions
Intuition: K-nearest neighbors
Conceptually, k-NN algorithm plots points on a graph. It keeps track of the class or in our case if a patient has breast cancer or not. When a new point/sample/patient is provided, their features or measurements are plotted, and depending on the closest points, a class is assigned. A picture is worth a thousand words, right?
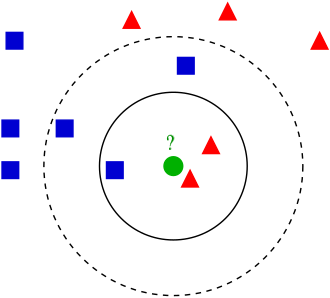
Let’s say the red triangles are patients that we know do NOT have breast cancer and the blue square represents patients who are confirmed to have breast cancer. If the green circle is a new point or patient introduced, we measure its distance from its closest neighbors. Now depending on how we set it up, determines how we decide on the new point. If I tell the algorithm that the green circle depends on its closest TWO neighbors, then we will assign it as a red triangle or ‘no breast cancer’. If we decide to accept 5 closest neighbors, then the green circle would be assigned as a blue circle and classified as having breast cancer.
Hyperparameters
Hyperparameters are the settings used to run a model. Some parameters affect how conservative the predictions are. A conservative model can be generalizable to the wild/unseen data and less likely to overfit to the training data set. Hyperparameters are specific to the algorithm. In this use case, we will define feature_dim, k, sample size, and predictor type.
Specifics to the hypermeters can be found in the AWS kNN documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/kNN_hyperparameters.html
Run the Training Job
Progress can be checked through the prompt below and you can check via SageMaker console under Training/Training Jobs. The SageMaker SDK offers APIs where you can programmatically request the status of the training job. See: https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeTrainingJob.html

Create Endpoint
An Endpoint is an instance that hosts the k-NN created from the training. We define the size of the instance and request the instance via the deploy method. Once it is created, we can send ‘inferences’ or ‘predictions’ to the instance and we will get a response back depending on how it is configured. In this case, we’ll receive text/csv back. But we can consider other options such as json.
Make Inferences

Evaluate the results
There are various objective metrics to evaluate the performance of our model. Accuracy is commonly understood, but there are other metrics such as recall and precision. If we want to minimize type I errors, then we would want to use precision as an objective metric. If we want to minimize type II errors, then we want to optimize our model to maximize recall.
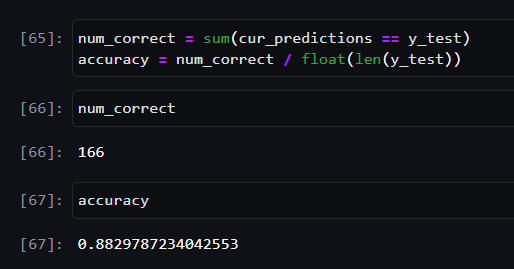
When comparing the model’s prediction against the hold-out test set, the model is accurate 88% of the time.
Perform Clean-Up Tasks
Once we’re done making predictions, we must delete our endpoint. Otherwise, AWS will continue to charge us for using their resources.
Take Aways
I acknowledge there’s much to refine in this notebook and they are referenced in the ‘looking ahead’ portion. The goal is to run k-NN from start to finish in AWS SageMaker.
Concepts like protobuf are new to me. However, its capabilities allow a scalable deployment for machine learning applications which coincides with cost-savings when operating.
Aside from learning the concept of k-NN and its inputs and parameters, I also had to learn to navigate through AWS SageMaker. It is recommended to pursue AWS Certified Cloud Practitioner and/or AWS Certified Solutions Architect — Associate to get a basic understanding of terminology and public cloud technology and capabilities. I know folks may be concerned about vendor-lockin, but the good news is that concepts and technology are similar in the market. I intend to branch out to Azure and GCP, but I would like to be an expert in at least one first.
Looking ahead: In future versions of this project, I would like to add the following. Open to suggestions.
- Hyperparameter tuning
- k-folds in the training data
- Normalizing the feature set
- Visualize distributions among the features
- Evaluate the model with other metrics such as AUC and ROC.
Full notebook:
Github repository. Feel free to modify and distribute.
Licensed under Apache-2.0
